OpusLM_7B_Anneal
综合介绍
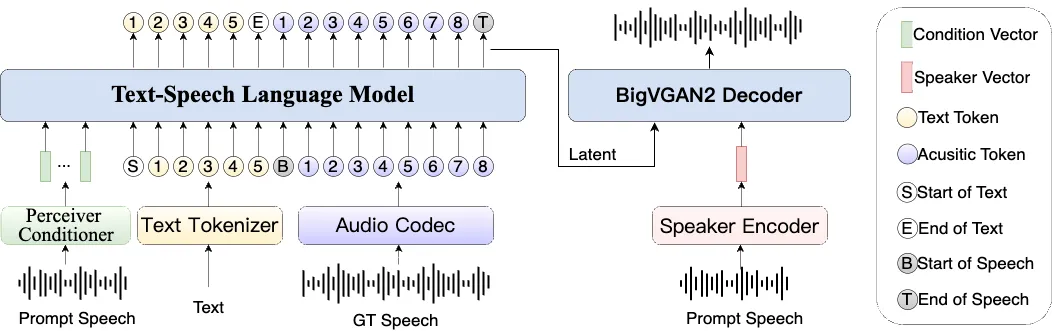
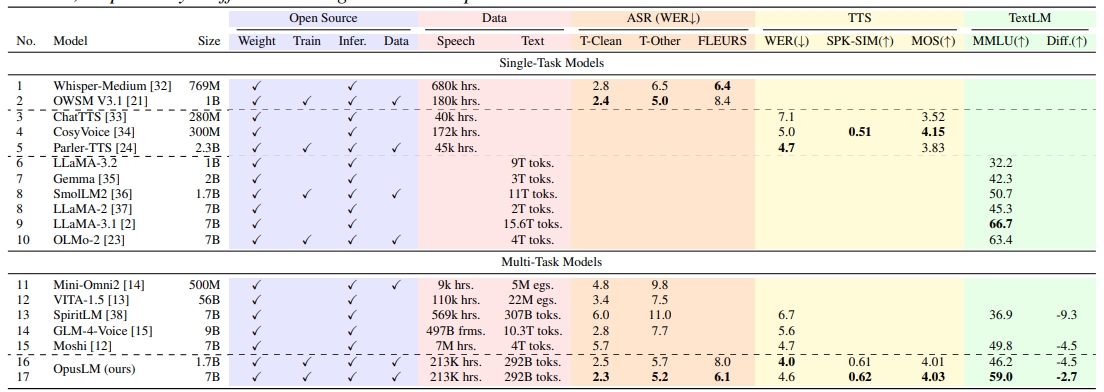
OpusLM_7B_Anneal 是一个由 ESPnet 团队开发的 70 亿参数规模的语音语言模型。 它属于 OpusLM 模型家族,这类模型是一种开放的基础语音语言模型(SpeechLM),其核心设计是能同时处理语音和文本两种模态。 OpusLM 模型基于仅解码器的 Transformer 架构,通过在大量的文本-语音配对数据和纯文本数据上进行持续预训练,使其不仅能执行自动语音识别(ASR)和文本到语音合成(TTS)任务,还保留了很强的纯文本处理能力。 该模型使用了包含文本、语义和声学三种标记的联合词汇表,能够理解和生成多码流的离散化(token)信息。 OpusLM_7B_Anneal 在语音识别和语音合成任务上表现出色,同时在衡量语言模型文本能力的 MMLU 基准测试中也取得了有竞争力的分数。
功能列表
- 统一语音和文本处理:模型采用单一架构,可以无缝处理和生成语音及文本数据。
- 自动语音识别 (ASR):能够将输入的语音内容转换为文字。在 LibriSpeech Test-Clean 测试集上,其 ASR 的词错误率(WER)达到了 2.3%。
- 文本到语音合成 (TTS):能够将输入的文本合成为自然的语音。在 LibriSpeech Test-Clean 测试集上,其 TTS 的词错误率(WER)为 4.0%。
- 文本处理能力:该模型保留了其基座文本大模型的能力,在 MMLU 基准测试中得分 59.0,能够完成各类自然语言理解和生成任务。
- 多码流处理:模型能够接收并生成由文本、语义和声学标记组成的多流离散化序列。
使用帮助
OpusLM 模型家族基于 ESPnet-SpeechLM 工具包构建,使用时需要依赖 ESPnet 的环境和流程。 虽然 OpusLM_7B_Anneal 模型卡片没有提供直接的推理代码,但可以参考其所属的 ESPnet 框架的通用使用方法。ESPnet 是一个端到端的语音处理工具包,通常的使用流程涉及环境安装、数据准备、模型训练和推理。
1. 环境安装
首先,需要克隆 ESPnet 的 GitHub 仓库并安装其依赖。ESPnet 依赖于 PyTorch。
# 克隆 ESPnet 仓库
git clone https://github.com/espnet/espnet
cd espnet/tools
# 安装依赖
./setup_anaconda.sh venv espnet 3.9
conda activate espnet
./installers/install_torch.sh
pip install -e ".[test]"
pip install -e ".[doc]"
# 检查安装是否成功
python check_install.py
2. 使用 ESPnet-SpeechLM 工具包
OpusLM 是使用 ESPnet-SpeechLM 工具包构建的,该工具包将不同的语音任务统一为序列建模问题。 使用这类模型通常遵循 ESPnet 的 recipe(脚本集)风格。
3. 模型推理示例(通用 SpeechLM 流程)
由于没有 OpusLM_7B_Anneal 的专属推理脚本,以下将展示一个基于 ESPnet 进行语音识别(ASR)的通用代码框架。你需要将模型名称和相关配置替换为 espnet/OpusLM_7B_Anneal。
首先,加载模型。在 Python 脚本中,你可以使用 speech_singleton_executor 来加载预训练模型并进行推理。
import soundfile
from espnet2.bin.speech_translation_inference import SpeechTranslationInference
# 初始化模型推理器
# 注意:这里的模型名称和配置需要根据 OpusLM_7B_Anneal 的实际情况进行调整
# 你可能需要指定 model_tag, asr_train_config, asr_model_file 等参数
speech2text = SpeechTranslationInference(
model_tag="espnet/OpusLM_7B_Anneal", # 假设模型支持此方式加载
device="cuda:0" # 或者 "cpu"
)
# 读取一个音频文件
audio, sample_rate = soundfile.read("path/to/your/audio.wav")
# 执行推理
# 模型的具体调用方式可能不同,可能需要指定任务类型(如 asr, tts)
results = speech2text(audio)
# 输出结果
# 结果的格式取决于模型输出,通常是一个包含文本的元组或字典
text = results[0][0]
print(f"识别结果: {text}")
4. 执行文本到语音(TTS)任务
如果模型支持 TTS,其调用方式会略有不同,通常需要加载一个 TTS 推理类。
from espnet2.bin.tts_inference import Text2Speech
# 初始化 TTS 模型
# 同样,这里的参数需要适配 OpusLM_7B_Anneal 模型
text2speech = Text2Speech.from_pretrained(
model_tag="espnet/OpusLM_7B_Anneal", # 假设模型支持此方式加载
device="cuda:0"
)
# 输入文本
text_to_synthesize = "你好,这是一个测试句子。"
# 执行语音合成
synthesis_result = text2speech(text_to_synthesize)
wav = synthesis_result["wav"]
# 保存音频文件
soundfile.write("output.wav", wav.numpy(), text2speech.fs, "PCM_16")
print("音频已保存至 output.wav")
重要提示:
- 上述代码是基于 ESPnet 工具包通用功能的示例,
OpusLM_7B_Anneal模型的具体加载和使用方式可能需要查阅其在 ESPnet 项目中的相关recipe或文档。 - 由于 Hugging Face 页面缺乏模型卡片,最准确的使用方法通常位于其 GitHub 仓库的示例或说明文档中。 你需要访问
https://github.com/espnet/espnet并寻找与OpusLM或SpeechLM相关的项目。
应用场景
- 自动语音识别 (ASR)将会议录音、课堂演讲、播客等音频内容快速准确地转写为文字,方便后续的记录、存档和内容分析。
- 文本到语音合成 (TTS)为有声读物、虚拟助手、导航系统等应用提供高质量、听感自然的语音输出。也可以用于为视障用户提供屏幕朗读功能。
- 语音交互智能体作为语音交互系统的核心,驱动能够通过语音进行对话和操作的智能应用。例如,可以构建一个能听懂指令并用语音反馈结果的智能家居控制器。
- 多语言语音翻译虽然当前资料未明确强调,但 ESPnet 框架本身支持语音翻译(Speech Translation)任务,具备处理多语言场景的潜力。
QA
- OpusLM 和其他语言模型(如 LLaMA)有什么区别?OpusLM 是一个多模态模型,专门设计用于同时处理语音和文本数据。 而像 LLaMA 这样的模型主要是纯文本语言模型,原生不具备处理原始语音信号的能力。OpusLM 在一个统一的框架内集成了语音识别和语音合成功能,这是一个关键区别。
- 什么是 ESPnet?ESPnet 是一个开源的端到端语音处理工具包,基于 PyTorch 构建。 它提供了完整的实验流程,覆盖了从数据处理、模型训练到推理的各个环节,支持语音识别、文本到语音、语音翻译等多种任务。 OpusLM 就是使用 ESPnet 中的
SpeechLM工具包开发出来的。 - 如何使用
OpusLM_7B_Anneal模型?使用此模型需要借助 ESPnet 工具包。 用户需要先安装 ESPnet 环境,然后利用其提供的推理脚本来加载模型并执行任务。由于 Hugging Face 页面信息有限,具体的操作细节需要参考 ESPnet 在 GitHub 上的项目文档和示例代码。